Backup and restore a SQL 2019 Big Data Cluster using Ansible
This blog will focus on creating a backup and being able to restore that backup for a Microsoft SQL 2019 Big Data cluster using Ansible and the Pure Storage FlashArray. As you might know SQL Big Data clusters run in Kubernetes for the most part, and use multiple StatefulSets to store the data (as shown in the diagram below).

But first, why did I created these Ansible playbooks? Well, have you ever experienced that moment when a colleague posts a question in an internal group and you think Oh wauw, I’m now part of the Peanut gallery? Or more to the point, the second thought where you think Well that can’t be too hard, can it? However then you run into some issues not related to the problem you’re trying to solve but some quirky behaviors of the tool you use, in this case Ansible or more specifically Jinja2.
This blog will focus on solving the following question from my colleague:
Pre-empting a potential POC [proof-of-concept] question for a SQL Server 2019 big data cluster. This screen capture illustrates the PVs for a big data cluster I currently have set up in my lab, it appears that the names of the PVs are randomly generated, however I can go off the claim name. My ask is this, I require the ability to stand up a big data cluster, snapshot all the persistent volumes, blow it away, create a new one and then overwrite the volumes with the snapshots. What would my fellow esteemed “Peanut gallery” members recommend for doing this, Ansible, bonus points awarded to anyone with a blog or material that goes into this.
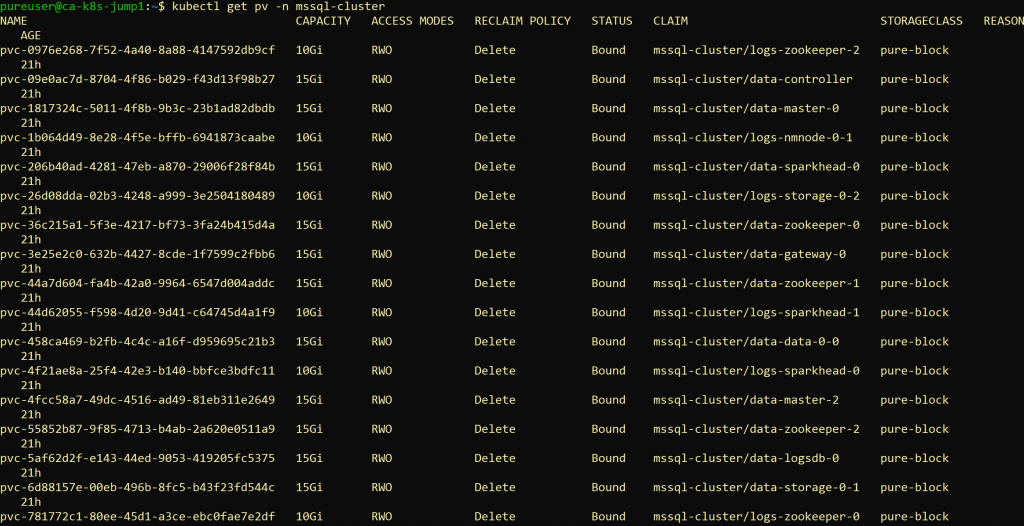
So looking at the picture we can see quite a few Persistent Volumes (PV), indeed with seemingly random names. However the PV also lists the associated Persistent Volume Claim (PVC), which name makes a lot more sense. It actually shows us that we are talking about multiple StatefulSets. Reading up on the Microsoft site, confirms this:
https://docs.microsoft.com/en-us/sql/big-data-cluster/view-cluster-status?view=sql-server-ver15
So what we want to achieve it to find all PVC’s related to the cluster, create a copy and use that copy to restore the cluster once we have a new cluster deployed. So our task (and the playbooks) will split in two parts, first a backup playbook and then a restore playbook.
Complete versions of the playbooks in this blog can be found here:
https://github.com/dnix101/purestorage/tree/master/ansible/SQL%20Big%20Data%20cluster
Backup playbook
In the backup playbook we want to create a clone of the current PV on the FlashArray (or Cloud Block Store). The first step is to identify which PVC’s to clone in Kubernetes. My first idea was to go through all the StatefulSets and find the PVC’s for those StatefulSets and then clone those PVC’s. However the way Kubernetes describes StatefulSets and their volumes including the fact that Ansible does not really support nested loops made this approach difficult. I then realised that since all PVC’s created by a StatefulSet would inherit their labels AND that Microsoft uses a specific label:
MSSQL_CLUSTER=<clustername>
Therefor I can easily list all PVC’s for the MSSQL Big Data Cluster using the combination of it’s namespace and that label, where my cluster name is mssql-cluster and the namespace I use is also mssql-cluster.
- name: Get list of PVC's for Microsoft SQL Big Data Cluster
k8s_info:
kind: PersistentVolumeClaim
namespace: "mssql-cluster"
label_selectors: "MSSQL_CLUSTER=mssql-cluster"
register: list_pvcThis will list all PVC’s to backup and store them as an array called list_pvc. Now that we have a JSON description of all our PVC’s we can use that to create a snapshot for each PV:
- name: Create (temporary) snapshot for each PVC
purefa_snap:
fa_url: "{{ fa_url }}"
api_token: "{{ fa_apitoken }}"
name: "{{ 'k8s-' + list_pvc | json_query('resources[' + ansible_loop.index0 | string + '].spec.volumeName') }}"<br> suffix: "my_backup_snap"
state: present
with_sequence: count="{{ list_pvc | json_query('resources') | count }}"
loop_control:
extended: yesWe use the Ansible module purefa_snap to create the snapshot. We need to specify the volume name, which is the “random” PV name prefixed with a PSO namespace (specified as namespace.pure in the values.yaml during the PSO installation), which by default is k8s. I use a Jinja2 json_query to find the PV name (spec.volumeName) for the PVC and use a loop to go through all PVC’s, one by one. The loop also uses a json_query to determine the count of PVC’s in the list_pvc variable.
Once the snapshot is created, I create a copy of the snapshot to a new volume on the FlashArray/Cloud Block Store. The Ansible task for this is quite similar to the previous one, looping through all PVC’s to clone the snapshot into a volume:
- name: Create clone for each PVC as backup
purefa_snap:
fa_url: "{{ fa_url }}"
api_token: "{{ fa_apitoken }}"
name: "{{ 'k8s-' + list_pvc | json_query('resources[' + ansible_loop.index0 | string + '].spec.volumeName') }}"
suffix: "my_backup_snap"
target: "{{ 'my_backup_vol--' + list_pvc | json_query('resources[' + ansible_loop.index0 | string + '].metadata.name') }}"
state: copy
overwrite: yes
with_sequence: count="{{ list_pvc | json_query('resources') | count }}"
loop_control:
extended: yesThe only thing I needed to add was the target volume name, which specifies the name of the backup volume to use. By using the PVC name (metadata.name), which is human readable and can be related to the PVC during the restore, I can create a volume clone that I can easily restore in the restore playbook.
Now my backup has completed and I can go ahead and destroy the Big Data Cluster and redeploy a fresh installation, to get ready for the next step… Restoring it.
Restore playbook
Restoring the backup in a fresh new cluster will require the following steps:
– Get a list of the PVC’s (same as for the backup);
– Get a list of the associated StatefulSets;
– Get the replica count for each StatefulSet;
– Scale all StatefulSets to 0 replica’s;
– Clone the backup volumes to overwrite the (new) PV’s;
– Scale the StatefulSets back to their original replica count.
I guess most steps make sense by themselves. However when overwriting a PV of a StatefulSet, you must make sure that the pod using the PV is stopped before overwriting. Otherwise the container would most likely crash. The way to stop the containers in a StatefulSet is to scale the replicas down to 0. Then we can overwrite the PVC’s and once done, scale the StatefulSets back to it’s original count.
We have already seen how we can get the list of PVC’s, so I’ll skip that step here (see the full playbook on Github for more details). Next we need to get the list of StatefulSets:
- name: Get StatefulSets
k8s_info:
kind: StatefulSet
namespace: "mssql-cluster"
label_selectors: "MSSQL_CLUSTER=mssql-cluster"
register: list_statefulsetsThis will list all StatefulSets of the cluster, and save them as a variable called list_statefulsets. Now that we have a JSON description of all our StatefulSets, we can use that to scale the StatefulSets down. This is where this exercise got interesting…
- name: Save current StatefulSets replica count
set_fact:
replicas: "{{replicas|default({}) | combine({list_statefulsets | json_query('resources[' + ansible_loop.index0 | string + '].metadata.name'): list_statefulsets | json_query('resources[' + ansible_loop.index0 | string + '].spec.replicas')})}}"
with_sequence: count="{{ list_statefulsets | json_query('resources') | count }}"
loop_control:
extended: yesTo create a array of all StatefulSets with the number of replica’s, we need some advanced Jinja2 as shown on line 3. Let break this down:
- replicas: We will store the list in the variable replicas;
- replicas|default({}) Since the replicas variable is new to Ansible, we’ll have to define it by using default({}), which defines replicas as a variable of the type array.
- combine(…) Here we use the python combine function to store the name of the StatefulSet (which we extract using json_query from list_statefulsets) as the key and the current replicas count (also extracted from list_statefulsets using json_query) as the value.
Using a loop to go through all StatefulSets, will result in an array replicas that contains a key/value for each StatefulSet and the replica count for that StatefulSet. Now that’s done, we can scale the number of replicas to 0 for all StatefulSets used by the cluster:
- name: Scale down StatefulSets relicas to 0
k8s:
name: "{{ list_statefulsets | json_query('resources[' + ansible_loop.index0 | string + '].metadata.name') }}"
namespace: "mssql-cluster"
state: present
definition:
apiVersion: apps/v1
kind: StatefulSet
spec:
replicas: 0
with_sequence: count="{{ list_statefulsets | json_query('resources') | count }}"
loop_control:
extended: yesNothing exceptional here I guess, just using the k8s module to patch the StatefulSets with spec.replicas = 0. Since we do not want to overwrite a volume while pods are still running, our next task is to wait for all pods to have been terminated.
- name: Wait for containers to stop
k8s_info:
kind: pod
namespace: "mssql-cluster"
label_selectors: "MSSQL_CLUSTER=mssql-cluster"
register: list_pods
until: "(list_pods | json_query('resources') | count) == 0"
retries: 20
delay: 5The task above will loop for 20 times waiting 5 seconds between each loop, counting the number of pods returned by Kubernetes. Once they are all stopped this will be 0 and our playbook will continue.
- name: Overwrite (new) PVC with backup
purefa_volume:
fa_url: "{{ fa_url }}"
api_token: "{{ fa_apitoken }}"
target: "{{ pso_namespace + '-' + list_pvcs | json_query('resources[' + ansible_loop.index0 | string + '].spec.volumeName') }}"
name: "{{ volcopy_prefix + '-' + list_pvcs | json_query('resources[' + ansible_loop.index0 | string + '].metadata.name') }}"
overwrite: yes
with_sequence: count="{{ list_pvcs | json_query('resources') | count }}"
loop_control:
extended: yesNow we can overwrite the PVC’s from our backup volumes, using the purefa_volume module. By now this should look quite straight forward, as we are using almost the same code used for the backup. Now the name is specified as the name of the backup volume and the target as the PVC name. By specifying the overwrite: yes option, we make sure that our PVC is overwritten with the contents of our backup volume.
Once this is done, we can scale the StatefulSets back to their original replicas count:
- name: Scale up StatefulSets to orginisal relica count
k8s:
api_version: "apps/v1"
kind: "StatefulSet"
name: "{{ item.key }}"
namespace: "{{ k8s_namespace }}"
definition:
spec:
replicas: "{{ item.value }}"
wait: yes
with_dict: "{{ replicas }}"
loop_control:
extended: yesThe task above looks quite straight forward, we are looping through our replicas key/value array and patch out StatefulSets using the k8s module to the original number of replicas. However this part has kept me busy for some time. The reason is that by default Jinja2 will return a string value in most cases (see more detail here) for a calculated value. The k8s module will only accept Integer values for replicas, and will break on execution if the replicas value is specified as a string.
My first attempt was to use the k8s_scale module, however that didn’t fly because it gave me other errors, which I won’t go into details for now. After quite some digging I found that in Ansible version 2.7 a new feature was introduced, which can be set using the jinja2_native option. Since this option can break existing playbooks and also can cause some issues with JSON to dict conversions, you need to enable it explicitly in the ansible.cfg or via an environment variable. I chose to add an ansible.cfg file in the directory of my playbooks, containing just the following lines:
[defaults] jinja2_native = true
This will enable the jinja2_native functionality, which makes sure that the Jinja2 value “{{ item.value }}” in line 9 of the k8s task above is now returned as an Integer and not as a String. Since the k8s module requires an Integer for replicas the command now finishes without problems.
Closing off
With that we have completed the backup AND the restore of the Microsoft SQL 2019 Big Data Cluster using Ansible playbooks and the Pure Storage FlashArray.
If this is something you want to try for yourself, checkout the SQL 2019 Big Data Cluster install guide here:
https://docs.microsoft.com/en-us/sql/big-data-cluster/deployment-guidance?view=sql-server-ver15
I have provided a full copy of my playbooks on GitHub here:
https://github.com/dnix101/purestorage/tree/master/ansible/SQL%20Big%20Data%20cluster
In these playbooks, I have moved all the configurable settings (eg. Kubernetes namespace, MS SQL cluster name, etc) to the settings.yaml file, so that you only need to configure the playbooks once and are able to use both the backup and restore playbooks straight away.
I hope this has been helpful to you! If you have any comments, please leave your thoughts below.